Probability space
In probability theory, a probability space or a probability triple is a mathematical construct that models a real-world process (or "experiment") consisting of states that occur randomly. A probability space is constructed with a specific kind of situation or experiment in mind. One proposes that each time a situation of that kind arises, the set of possible outcomes is the same and the probability levels are also the same.
A probability space consists of three parts:
- A sample space,
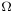 , which is the set of all possible outcomes.
, which is the set of all possible outcomes. - A set of events, where each event is a set containing zero or more outcomes.
- The assignment of probabilities to the events, that is, a function from events to probability levels.
An outcome is the result of a single execution of the model. Since individual outcomes might be of little practical use, more complex events are used to characterize groups of outcomes. The collection of all such events is a σ-algebra 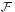 . Finally, there is a need to to specify each event's likelihood of happening. This is done this using the probability measure function, P. These three components
. Finally, there is a need to to specify each event's likelihood of happening. This is done this using the probability measure function, P. These three components 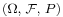 together constitute the probability space. A probability space is characterized as a “triple” because it has three components.
together constitute the probability space. A probability space is characterized as a “triple” because it has three components.
Once the probability space is established, it is assumed that “nature” makes its move and selects a single outcome, ω, from the sample space Ω. Then all the events in that contain the selected outcome ω (recall that each event is a subset of Ω) are said to “have occurred”. The selection performed by nature is done in such a way that if the experiment were to be repeated an infinite number of times, the relative frequencies of occurrence of each of the events would coincide with the probabilities prescribed by the function P.
The prominent Soviet mathematician Andrey Kolmogorov introduced the notion of probability space, together with other axioms of probability, in the 1930s. Nowadays alternative approaches for axiomatization of probability theory exist; see “Algebra of random variables”, for example.
This article is concerned with the mathematics of manipulating probabilities. The article probability interpretations outlines several alternative views of what "probability" means and how it should be interpreted. In addition, there have been attempts to construct theories for quantities that are notionally similar to probabilities but do not obey all their rules; see, for example, Free probability, Possibility theory, Negative probability and Quantum probability.
Contents |
Introduction
A probability space presents a model for a particular class of real-world situations. As with other models, its author ultimately defines which elements Ω, , and P will contain.
- The sample space Ω is a set of outcomes. An outcome is the result of a single execution of the model. Outcomes may be states of nature, possibilities, experimental results, and the like. Every instance of the real-world situation or run of the experiment must produce exactly one outcome. If outcomes of different runs of an experiment differ in any way that matters, they are distinct outcomes. What differences matter depends, of course, on the kind of analysis we want to do. This leads to different choices of sample space.
- The σ-algebra . is a collection of all and only events (not necessarily elementary) we would like to consider. Here, an "event" is a set of zero or more outcomes, i.e., a subset of the sample space. An event is considered to have "happened" when the outcome is a member of the event. Since the same outcome may be a member of many events, it is possible for many events to have happened given a single outcome. For example, when the trial consists of throwing two dice, the set of all outcomes with a sum of 7 pips may constitute an event. Outcomes with an odd number of pips may constitute another event. If the outcome is the element of the elementary event of two pips on the first die and five on the second, then both of the events of "7 pips" and "odd number of pips" have also happened.
- The probability measure P is a function returning an event's probability. A probability is a real number between zero (the event cannot happen in any trial) and one (the event must happen in every trial). Thus P is a function
![\scriptstyle P:\ \mathcal{F} \rightarrow [0,1]](/2010-wikipedia_en_wp1-0.8_orig_2010-12/I/ca27094653a91c6dd828da93cd5ee1bc.png) . The probability measure function must satisfy a simple requirement: the probability of a union of two disjoint events must be equal to the sum of probabilities of each of these events. For example, if two events are Heads and Tails, then the probability of Heads-or-Tails must be equal to the sum of probabilities for Heads and Tails).
. The probability measure function must satisfy a simple requirement: the probability of a union of two disjoint events must be equal to the sum of probabilities of each of these events. For example, if two events are Heads and Tails, then the probability of Heads-or-Tails must be equal to the sum of probabilities for Heads and Tails).
Not every subset of the sample space Ω must necessarily be considered an event: Some of the subsets are simply not of interest, others cannot be “measured”. This is not so obvious in a case like a coin toss. In a different example, one could consider javelin throw lengths, where the events typically are intervals like "between 60 and 65 meters" and unions of such intervals, but not "irrational numbers between 60 and 65 meters"
Definition
In short, a probability space is a measure space such that the measure of the whole space is equal to one.
The expanded definition is following: a probability space is a triple consisting of:
- the sample space Ω — an arbitrary non-empty set,
- the σ-algebra ⊆ 2Ω (also called σ-field) — a set of subsets of Ω, called events, such that:
- contains an empty set: ∅∈,
- is closed under complements: if A∈, then also (Ω∖A)∈,
- is closed under countable unions: if Ai∈ for i=1,2,…, then also (∪iAi)∈
- The corollary from the previous two properties and the De Morgan’s law is that is also closed under countable intersections: if Ai∈ for i=1,2,…, then also (∩iAi)∈
- The corollary from the previous two properties and the De Morgan’s law is that
- the probability measure P: →[0,1] — a function on such that:
- P is countably additive: if {Ai}⊆ is a countable collection of pairwise disjoint sets, then P(⊔Ai) = ∑P(Ai), where “⊔” denotes the disjoint union,
- the measure of entire sample space is equal to one: P(Ω) = 1.
- P is countably additive: if {Ai}⊆
Discrete case
Discrete probability theory needs only at most countable sample spaces Ω, which makes the foundations much less technical. Probabilities can be ascribed to points of Ω by the probability mass function p: Ω→[0,1] such that ∑ω∈Ω p(ω) = 1. All subsets of Ω can be treated as events (thus, = 2Ω is the power set). The probability measure takes the simple form
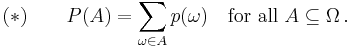
The greatest σ-algebra = 2Ω describes the complete information. In general, a σ-algebra ⊆ 2Ω corresponds to a finite or countable partition Ω = B1 ⊔ B2 ⊔ …, the general form of an event A ∈ being A = Bk1 ⊔ Bk2 ⊔ … (here ⊔ means the disjoint union.) See also the examples.
The case p(ω) = 0 is permitted by the definition, but rarely used, since such ω can safely be excluded from the sample space.
General case
If Ω is uncountable, still, it may happen that p(ω) ≠ 0 for some ω; such ω are called atoms. They are an at most countable (maybe, empty) set, whose probability is the sum of probabilities of all atoms. If this sum is equal to 1 then all other points can safely be excluded from the sample space, returning us to the discrete case. Otherwise, if the sum of probabilities of all atoms is less than 1 (maybe 0), then the probability space decomposes into a discrete (atomic) part (maybe empty) and a non-atomic part.
Non-atomic case
If p(ω) = 0 for all ω∈Ω then equation (∗) fails: the probability of a set is not the sum over its elements, which makes the theory much more technical. Initially the probabilities are ascribed to some “generator” sets (see the examples). Then a limiting procedure allows to ascribe probabilities to sets that are limits of sequences of generator sets, or limits of limits, and so on. All these sets are the σ-algebra . For technical details see Caratheodory’s extension theorem. Sets belonging to are called measurable. In general they are much more complicated than generator sets, but much better than non-measurable sets.
Examples
Discrete examples
Example 1
If the experiment consists of just one flip of a perfect coin, then the outcomes are either heads or tails: Ω = {H, T}. The σ-algebra = 2Ω contains 2² = 4 events, namely: {H} – “heads”, {T} – “tails”, {} – “neither heads nor tails”, and {H,T} – “either heads or tails”. So, = {{}, {H}, {T}, {H,T}}. There is a fifty percent chance of tossing heads, and fifty percent for tails. Thus the probability measure in this example is P({}) = 0, P({H}) = 0.5, P({T}) = 0.5, P({H,T}) = 1.
Example 2
The fair coin is tossed three times. There are 8 possible outcomes: Ω = {HHH, HHT, HTH, HTT, THH, THT, TTH, TTT} (here “HTH” for example means that first time the coin landed heads, the second time tails, and the last time heads again). The complete information is described by the σ-algebra = 2Ω of 28 = 256 events, where each of the events is a subset of Ω.
Alice knows the outcome of the second toss only. Thus her incomplete information is described by the partition Ω = A1 ⊔ A2 = {HHH, HHT, THH, THT} ⊔ {HTH, HTT, TTH, TTT}, and the corresponding σ-algebra Alice = {{}, A1, A2, Ω}. Brian knows only the total number of tails. His partition contains four parts: Ω = B0 ⊔ B1 ⊔ B2 ⊔ B3 = {HHH} ⊔ {HHT, HTH, THH} ⊔ {TTH, THT, HTT} ⊔ {TTT}; accordingly, his σ-algebra Brian contains 24 = 16 events.
The two σ-algebras are incomparable: neither Alice ⊆ Brian nor Brian ⊆ Alice; both are sub-σ-algebras of 2Ω.
Example 3
If 100 voters are to be drawn randomly from among all voters in California and asked whom they will vote for governor, then the set of all sequences of 100 Californian voters would be the sample space Ω. We assume that sampling without replacement is used: only sequences of 100 different voters are allowed. For simplicity an ordered sample is considered, that is a sequence {Alice, Brian} is different from {Brian, Alice}. We also take for granted that each potential voter knows exactly his future choice, that is he/she doesn’t choose randomly.
Alice knows only whether or not Arnold Schwarzenegger has received at least 60 votes. Her incomplete information is described by the σ-algebra Alice that contains: (1) the set of all sequences in Ω where at least 60 people vote for Schwarzenegger; (2) the set of all sequences where fewer than 60 vote for Schwarzenegger; (3) the whole sample space Ω; and (4) the empty set ∅.
Brian knows the exact number of voters who are going to vote for Schwarzenegger. His incomplete information is described by the corresponding partition Ω = B0 ⊔ B1 … ⊔ B100 (though some of these sets may be empty, depending on the Californian voters…) and the σ-algebra Brian consists of 2101 events.
In this case Alice’s σ-algebra is a subset of Brian’s: Alice ⊂ Brian. The Brian’s σ-algebra is in turn the subset of the much larger “complete information” σ-algebra 2Ω consisting of 2n(n−1)…(n−99) events, where n is the number of all potential voters in California.
Non-atomic examples
Example 4
A number between 0 and 1 is chosen at random, uniformly. Here Ω = [0,1], is the σ-algebra of Borel sets on Ω, and P is the Lebesgue measure on [0,1].
In this case the open intervals of the form (a,b), where 0<a<b<1, could be taken as the generator sets. Each such set can be ascribed the probability of P((a,b)) = (b−a), which generates the Lebesgue measure on [0,1], and the Borel σ-algebra on Ω.
Example 5
A fair coin is tossed endlessly. Here one can take Ω = {0,1}∞, the set of all infinite sequences of numbers 0 and 1. Cylinder sets {(x1,x2,…)∈Ω: x1=a1, …, xn=an} may be used as the generator sets. Each such set describes an event in which the first n tosses have resulted in a fixed sequence (a1, …, an), and the rest of the sequence may be arbitrary. Each such event can be naturally given the probability of 2−n.
These two non-atomic examples are closely related: a sequence (x1,x2,…) ∈ {0,1}∞ leads to the number 2−1x1 + 2−2x2 + … ∈ [0,1]. This is not a one-to-one correspondence between {0,1}∞ and [0,1] however: it is an isomorphism modulo zero, which allows for treating the two probability spaces as two forms of the same probability space. In fact, all non-pathologic non-atomic probability spaces are the same in this sense.
Related concepts
Probability distribution
Any probability distribution defines a probability measure.
Random variables
A random variable X is a measurable function X: Ω→S from the sample space Ω to another measurable space S called the state space.
The notation Pr(X∈A) is a commonly used shorthand for P({ω∈Ω: X(ω)∈A}).
Defining the events in terms of the sample space
If Ω is countable we almost always define as the power set of Ω, i.e. = 2Ω which is trivially a σ-algebra and the biggest one we can create using Ω. We can therefore omit ℱ and just write (Ω,P) to define the probability space.
On the other hand, if Ω is uncountable and we use = 2Ω we get into trouble defining our probability measure P because is too “large”, i.e. there will often be sets to which it will be impossible to assign a unique measure, giving rise to problems like the Banach–Tarski paradox. In this case, we have to use a smaller σ-algebra , for example the Borel algebra of Ω, which is the smallest σ-algebra that makes all open sets measurable.
Conditional probability
Kolmogorov’s definition of probability spaces gives rise to the natural concept of conditional probability. Every set A with non-zero probability (that is, P(A) > 0) defines another probability measure
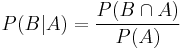
on the space. This is usually pronounced as the “probability of B given A”.
For any event B such that P(B) > 0 the function Q defined by Q(A) = P(A|B) for all events A is itself a probability measure.
Independence
Two events, A and B are said to be independent if P(A∩B)=P(A)P(B).
Two random variables, X and Y, are said to be independent if any event defined in terms of X is independent of any event defined in terms of Y. Formally, they generate independent σ-algebras, where two σ-algebras G and H, which are subsets of F are said to be independent if any element of G is independent of any element of H.
Mutual exclusivity
Two events, A and B are said to be mutually exclusive or disjoint if P(A∩B) = 0. (This is weaker than A∩B = ∅, which is the definition of disjoint for sets).
If A and B are disjoint events, then P(A∪B) = P(A) + P(B). This extends to a (finite or countably infinite) sequence of events. However, the probability of the union of an uncountable set of events is not the sum of their probabilities. For example, if Z is a normally distributed random variable, then P(Z=x) is 0 for any x, but P(Z∈R) = 1.
The event A∩B is referred to as “A and B”, and the event A∪B as “A or B”.
See also
- Sigma-algebra
- Space (mathematics)
- Measure space
- Fuzzy measure theory
- Standard probability space
- Filtered probability space
Bibliography
- Pierre Simon de Laplace (1812) Analytical Theory of Probability
-
- The first major treatise blending calculus with probability theory, originally in French: Théorie Analytique des Probabilités.
- Andrei Nikolajevich Kolmogorov (1950) Foundations of the Theory of Probability
-
- The modern measure-theoretic foundation of probability theory; the original German version (Grundbegriffe der Wahrscheinlichkeitrechnung) appeared in 1933.
- Harold Jeffreys (1939) The Theory of Probability
-
- An empiricist, Bayesian approach to the foundations of probability theory.
- Edward Nelson (1987) Radically Elementary Probability Theory
-
- Discrete foundations of probability theory, based on nonstandard analysis and internal set theory. downloadable. http://www.math.princeton.edu/~nelson/books.html
- Patrick Billingsley: Probability and Measure, John Wiley and Sons, New York, Toronto, London, 1979.
- Henk Tijms (2004) Understanding Probability
-
- A lively introduction to probability theory for the beginner, Cambridge Univ. Press.
- David Williams (1991) Probability with martingales
-
- An undergraduate introduction to measure-theoretic probability, Cambridge Univ. Press.
- Gut, Allan (2005). Probability: A Graduate Course. Springer. ISBN 0387228330.
- Sazonov, V.V. (2001), "Probability space", in Hazewinkel, Michiel, Encyclopaedia of Mathematics, Springer, ISBN 978-1556080104, http://eom.springer.de/P/p074960.htm
- Weisstein, Eric W., "Probability space" from MathWorld.
External links
- Virtual Laboratories in Probability and Statistics (principal author Kyle Siegrist), especially, Probability Spaces
- Citizendium